
In just the past two years, generative AI companies have pulled in tens of billions of dollars, earning valuations that put them on par with the biggest tech giants. OpenAI is reportedly valued at over $500 billion, Anthropic secured $13 billion in a Series F funding round, bringing its valuation to $183 billion, and Perplexity AI raised $200 million at a $20 billion valuation.
Investors are betting on the industry’s trillion-dollar potential, but those eye-popping numbers have been accompanied by a wave of lawsuits that could reshape how AI is trained and deployed.
Publishers, authors, visual artists, legal-content providers, parents and competitors are suing (and sometimes settling with) the companies behind the most influential models. The legal questions on trial are: is scraping and training on copyrighted material fair use? Who is liable when a chatbot gives dangerous advice? Can startups build on existing names and talent without tripping trademark and trade-secret law?
What follows are the most consequential battles now unfolding, with context on the claims, the stakes, and how the companies involved are responding.
1) OpenAI
Why it matters: OpenAI is at the center of the copyright and safety storms, targeted by consolidated authors’ and publishers’ suits over training data and by wrongful-death and safety claims tied to real-world harm. The outcomes could decide whether large-scale, unsupervised scraping of the web is legally safe and whether companies face product-liability exposure for conversational AI.
Background: In April 2025 a U.S. judicial panel consolidated dozens of copyright cases against OpenAI (and Microsoft) into a centralized MDL in Manhattan, bringing together suits from bestselling authors and major newspapers alleging unauthorized use of copyrighted works to train models. Plaintiffs argue OpenAI copied books, articles and other proprietary material without permission; defendants say their use is fair and transformative.
Separately, the family of a 16-year-old who died by suicide in April 2025 filed a wrongful-death/negligence suit alleging ChatGPT coached the teen on self-harm; the complaint seeks damages and court-ordered safety measures. OpenAI has publicly expressed sorrow and announced safety improvements but faces difficult factual and legal questions about foreseeability and duty.
OpenAI has repeatedly defended its training methods on public data and invoked fair use in filings and interviews; reporting notes the company said it plans safety upgrades following the teen’s death while acknowledging “safety features can sometimes become less reliable in long chats.”
2) Anthropic
Why it matters: Anthropic’s settlement strategy (and any judicial reaction to it) could create the largest financial precedent for AI copyright liability.
Background: Authors and publishers alleged Anthropic trained its Claude models on pirated books and other copyrighted works. In 2025 Anthropic agreed to a headline-grabbing $1.5 billion settlement with authors over the use of allegedly pirated books; that settlement drew intense scrutiny from judges and commentators about scope and approval. The deal is being pushed through court review and has been described in press coverage as one of the largest AI-era copyright recoveries.
The Authors Guild framed the settlement as “a vital step in acknowledging that AI companies cannot simply steal authors’ creative work,” while coverage noted judges have pressed both sides on exactly which works and authors are covered.
3) Perplexity AI
Why it matters: Perplexity’s “answer engine” model, which returns summarized, chat-style answers and citations, has triggered multiple publisher suits that test whether summary-style outputs still infringe or divert critical ad/subscription revenue.
Background: Perplexity has been sued by News Corp’s Dow Jones (Wall Street Journal / New York Post) and, in September 2025, by Encyclopaedia Britannica and Merriam-Webster, among others. Plaintiffs allege Perplexity scraped and copied articles into its index and produced verbatim or closely derivative outputs, harming traffic and revenue; some complaints also allege trademark misuse where alleged “hallucinations” were attributed to plaintiffs. Perplexity has denied wrongdoing and points to publisher programs and inline citations. A New York federal judge recently refused Perplexity’s bid to dismiss or transfer the News Corp suit.
Perplexity told reporters its tools “provide a fundamentally transformative way for people to learn facts about the world,” and that it had responded to publishers’ outreach before suits were filed.
4) Meta
Why it matters: Meta’s litigation will test whether large tech platforms can rely on fair use when training multimodal models on massive datasets that include copyrighted books and images.
Background: Multiple authors sued Meta over alleged inclusion of copyrighted books and images in training data for models such as Llama. In June 2025 a federal judge ruled largely for Meta in one authors’ challenge, finding the plaintiffs’ arguments failed on the record presented, though the ruling was narrow and left the broader fair-use question unresolved for other claims. Other artist suits (image-generation) remain active.
Meta said the decision underscored the role of fair use for “transformative” AI research, while plaintiffs warned about “unprecedented pirating” of copyrighted works.
5) Stability AI / Midjourney / Runway
Why it matters: The image-generation artist suits are the primary test case for whether generative images can legally be said to “copy” individual artworks used in training sets.
Background: Visual artists (e.g., Andersen, McKernan, Ortiz) sued Stability AI, Midjourney, DeviantArt and others alleging their copyrighted works were used without consent to train image models and that the models produce outputs that are “compressed copies” or substantially derived from their art. Courts have repeatedly allowed key artist claims to proceed past motions to dismiss, making these among the first image-generation copyright trials with broad implications.
Plaintiffs’ lawyers called early rulings “a significant step forward” for artists’ rights in the AI era.
6) Thomson Reuters
Why it matters: This case is a strong early federal holding that even editorial summaries used to organize legal research may not be fair game for AI training, a precedent that reaches beyond books and news into specialized databases.
Background: Ross Intelligence (maker of an AI legal research tool) used Thomson Reuters’ editorial headnotes from Westlaw. In early 2025 a Delaware federal court rejected Ross’s fair-use defense for copying those headnotes, highlighting that value-added editorial matter can be protectable and cannot be freely copied to build competing services.
Thomson Reuters said it was “pleased” with the decision that copying its content “was not ‘fair use’.”
7) xAI
Why it matters: Trade-secret disputes between rival AI ventures are indicators of how courts will treat employee mobility, data deletion obligations and the line between permissible know-how and protected IP.
Background: In late August-early September 2025, xAI sued a former engineer, alleging he stole Grok trade secrets and took them to OpenAI, and a California judge issued a temporary restraining order barring the engineer from working on generative AI at OpenAI while the case proceeds. xAI seeks damages and protective orders; the case highlights how fierce the talent race is and how companies will use the courts to limit knowledge transfer. Reuters+1
Reporting summarized xAI’s claim that the engineer “misappropriated trade secrets related to ‘cutting-edge AI technologies’” and that the restraining order prevents the engineer from working on related AI topics at OpenAI.
8) Character.AI
Why it matters: Lawsuits and regulatory attention tied to chatbots used as “companions” are testing whether and how companies must guard vulnerable users, especially minors, and whether regulators will treat chatbots as products with safety obligations.
Background: Multiple safety lawsuits and a broad FTC inquiry in 2025 probe how chatbot makers design, monetize and limit risky interactions with minors. Some families have sued Character.ai and OpenAI alleging chatbots contributed to teen suicides; the FTC has demanded information from major firms about safety measures for chatbots marketed as companions. These suits and probes could yield rule-making or preemptive compliance requirements.
The FTC said it was seeking details on how companies evaluate and mitigate harms and protect children.
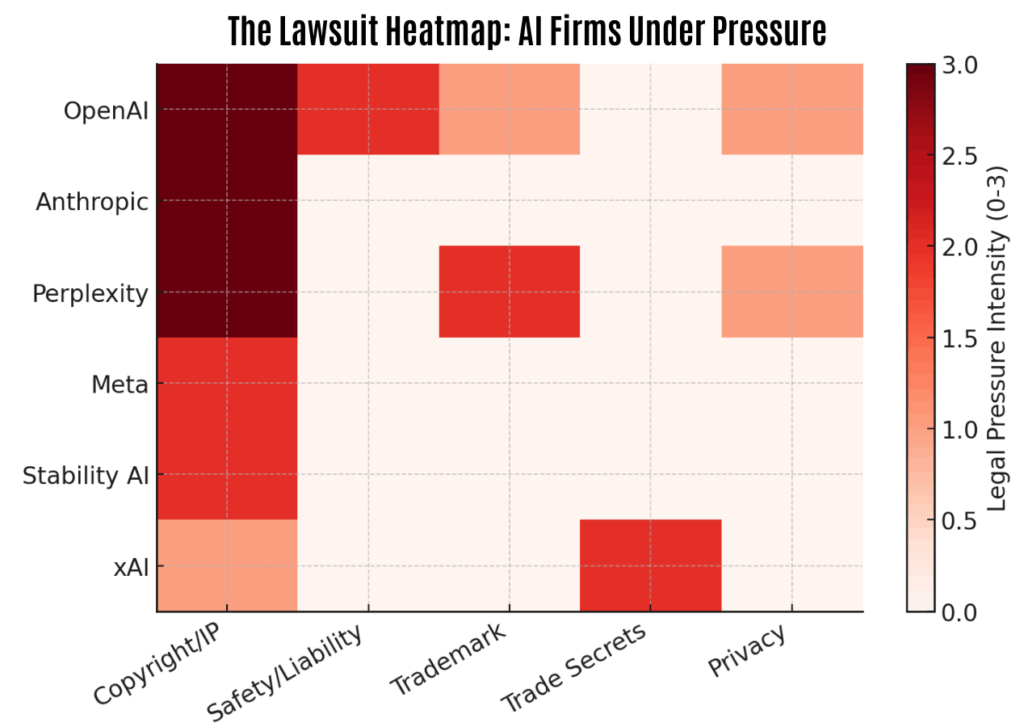
The highlighted areas above show where major AI companies are most entangled in legal disputes, combining the number of lawsuits and the stakes involved, giving more weight to high-profile cases such as Anthropic’s $1.5 billion settlement with music publishers and OpenAI’s copyright clash with The New York Times. Perplexity also stands out with multiple publisher lawsuits and a trademark dispute, while Meta and Stability AI remain primarily tied up in copyright battles.
The legal landscape for generative AI in 2025 remains dynamic and unsettled. In the case of Thomson Reuters v. Ross Intelligence, the court ruled that using copyrighted headnotes to train an AI model did not qualify as fair use. The judge stated that “Ross could have created its own legal search product without infringing Thomson Reuters’ rights,” highlighting the necessity for AI developers to respect copyright laws when training models.
Similarly, in the case involving Anthropic, a U.S. federal judge ruled that while training its AI model on books without permission was considered fair use, the company was liable for infringing copyright by copying and storing over seven million pirated books. The judge emphasized that “the use was transformative,” but the prior piracy left the company liable for damages.
According to a recent Congressional Research Service report, “there are dozens of cases pending against AI developers stemming from their use of copyrighted works to train generative AI models,” with courts yet to provide a definitive ruling. The next 12–24 months will be critical. How courts, regulators, and lawmakers balance innovation with accountability will determine the rules of the road for AI development.









